Among the most commonly used tools in the UNIX System are those for finding words in files, especially grep, fgrep, and egrep.
These commands search for text that matches a target or pattern that you specify You can use them to extract information from files, to search the output of a command for lines relating to a particular item, and to locate files containing a particular key word.
The three commands in the grep family are very similar. All of them print lines matching a target. They differ, however, in how you specify the search targets.
- grep is the most commonly used of the three commands. It lets you search for a target which may be one or more words or patterns containing wildcards and other regular expression elements.
- fgrep (fixed grep) does not allow regular expressions but does allow you to search for multiple targets.
- egrep (extended grep) takes a richer set of regular expressions, as well as allowing multiple target searches, and is considerably faster than grep.
grep
The grep command searches through one or more files for lines containing a target and then prints all of the matching lines it finds. For example, the following command prints all lines in the file “fcukthecode.txt” that contain the word “site”:
$ grep site fcukthecode.txt
hi!! welcome to the site.Note that you specify the target as the first argument and follow it with the names of the files to search. Think of the command as “ search for target in file .”
The target can be a phrase-that is, two or more words separated by spaces. If the target contains spaces, however, you have to enclose it in quotes to prevent the shell from treating the different words as separate arguments. The following searches for lines containing the phrase “Ready Player One” in the file ” ftc.txt ” :
$ grep "Ready Player One" ftc.txt
Have you guys seen the movie "Ready Player One", we will have the same animation and the technology of the film.Note that if the words “Ready”, “Player” and “One” appear on different lines (separated by a newline character), grep will not find them, because it looks at only one line at a time.
If you give grep two or more files to search, it includes the name of the file before each line of output. For example, the following command searches for lines containing the string “vacation” in all of the files in the current directory:
$ grep metaverse *
fcukthecode.txt:Hello Metaverse. Metaverse is the future, we will be able to watch anime in metaverse in near future and
ftc.txt:we see that video games have developed sooo sooo much. The same happens to metaverse. The output lists the names of the two files that contain the target word “metaverse”- fcukthecode.txt and ftc.txt -and the line(s) containing the target in each file.
You can use this feature to locate a file when you have forgotten its name but remember a key word that would identify it. For example, if you keep copies of your saved e-mail in a particular directory, you can use grep to find the one dealing with a particular subject by searching for a word or phrase that you know is contained in it. The following command shows how you can use grep to find a mail from someone named sony:
$ grep sony *
savedmail11/2: From: Sony (sony1102@)
savedmail04/3: well, sure. Metaverse is pretty, so IThis shows you that the letter you were looking for is in the file savedmail04/3.
ILLUSTRATION

Searching for Patterns Using Regular Expressions
The examples so far have used grep to search for specific words or strings of text, but grep also allows you to search for patterns that may match a number of different words or strings. The patterns for grep can be the same kinds of regular expressions. For example,
$ grep 'ch.*se' ftc.txtwill find entries containing “chinese” or “cheese”, or in fact any line that has a ch sometime before an se, including something like “Blanch for 45 seconds”.
In the preceding pattern, the dot (.) matches any character other than newline. The asterisk says that those characters may be repeated any number of times.
Together, .* indicates any string of any characters. Note that in this example the target pattern “ch.*se” is enclosed in single quotation marks.
This prevents the asterisk from being treated by the shell as a filename wildcard. In general, you need to use quotes around any regular expression containing a character that has special meaning for the shell.
Other regular expression symbols that are often useful in specifying targets for grep include the caret (^) and dollar sign ($), which are used to anchor words to the beginning and end of lines, and brackets ([ ]), which are used to indicate a class of characters.
The following example shows how these can be used to specify patterns as targets:
$ grep '^Chapters [1–9]$' fcukthecode.txtThis command finds all lines that contain just “Chapters n”, where n is a number from 1 to 9, in the file manuscript . The caret at the beginning and the dollar sign at the end indicate that the pattern must match the whole line. The brackets indicate that the target can include any one of the numbers from 1 to 9.
ILLUSTRATION

lists regular expression symbols that are useful in forming grep search patterns.
| Symbol | Definition | Example | Matches | |||
|---|---|---|---|---|---|---|
| . | Matches any single character. | th.nk | think, thank, thunk,etc. | |||
| \ | Quotes the following character. | script\.py | script.py | |||
| * | Previous item may occur zero or more times in a row. | ap*le | ale, apple, etc. | |||
| [a-z] | Matches any one of the characters in the range. | [0–9]* | any number: 0110, 27, 9876, etc. | |||
| $ | Anchor the pattern to the end of the string. | \.$ | any string ending in a period | |||
| ^ | Anchor the pattern to the beginning of a string. | ^ If | any string beginning with If | |||
| {n,m} | Previous item must occur at least n times but no more than m times. | \*{3,5} | ***, ****,***** | |||
| ( ) | Group a portion of the pattern. | script(\.pl)? | script, script.pl | |||
| [ ] | Matches any one of the characters inside. Frequently used with ranges. | [QqXx]* | Q, q, X, or x | |||
| [^] | Matches any character not inside the brackets. | [^AZaz] | any nonalphabetic character, such as 2 | |||
| + | Previous item occurs at least once, and maybe more. | \*+ | *, *****, etc. |
Options for grep
Normally, grep distinguishes between uppercase and lowercase. For example, the following command would find “Meta” but not “META” or “meta”:
$ grep Meta ftc.txtYou can use the −i (ignore case) option to find all lines containing a target regardless of uppercase and lowercase distinctions. This command finds all occurrences of the word “meta” regardless of capitalization:
$ grep −i meta ftc.txtILLUSTRATION

The −r option causes grep to recursively search files in all the subdirectories of the current directory.
$ grep −r "\.p[ly]" *
PerlScripts/quickmail.pl: # usage: quickmail.pl recipient subject contents
PythonScripts/zwrite.py: # usage: zwrite.py username$ grep -r "\.p[ly]" *
ftc_1/temp.py:#temp.py Main.py File
ftc_1/fcukthecode.py:fcukthecode.py Anime is Awesome!!!
temp.py:#temp.py Main.py FileThe backslash () prevents the dot (.) from being treated as a regular expression character-it represents a period here, so grep searches for a file containing “.pl” or “.py”.
Be careful: if the directory contains many subdirectories with many files in them, it can take a very long time for a command like this to complete.
Another useful grep option, −n, allows you to list the line number on which the target (here, while ) is found. For example,
$ grep −n while perlsample.pl
4: while (<>){
11: while ($n > −0) {$ grep -n print temp.py
6:print(os.path.split(os.getcwd()))One of the common uses of grep is to find which of several files in a directory deals with a particular topic. If all you want is to identify the files that contain a particular word or pattern, there is no need to print out the matching lines.
With the −l (list) option, grep suppresses the printing of matching lines and just prints the names of files that contain the target.
The following example lists all files in the current directory that include the word “Duckpond”:
$ grep −l Duckpond *
about.html
index.html
report.cgi$ grep -l print *
grep: ftc_1: Is a directory
grep: newfolder2: Is a directory
temp.pyILLUSTRATION

You can use this option with the shell command substitution feature to use these filenames as arguments to another UNIX System command. For example, the following command will use more to list all the files found by grep:
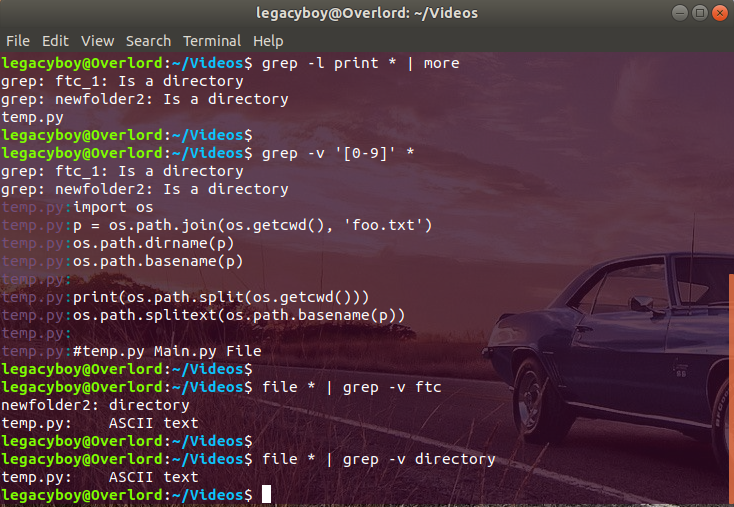
$ grep −l print * | moreBy default, grep finds all lines that match the target pattern. Sometimes, though, it is useful to find the lines that do not match a particular pattern. You can do this with the −v option, which tells grep to print all lines that do not contain the specified target.
This provides a quick way to find entries in a file that are missing a required piece of information. For example, suppose the file phonenums contains your personal phone book. The following command will print all lines in phonenums that do not contain numbers:
$ grep −v '[0–9]' phonenumsThe −v option can also be useful for removing unwanted information from the output of another command. The file command, you can use it to get a short description of the type of information contained in a file.
Because the file command includes the word “directory” in its output for directories, you could list all files in the current directory that are not directories by piping the output of file to grep −v, as shown in the following example:
$ file * | grep −v directory
temp.py: ASCII textILLUSTRATION